
Recently I've had a bit more time between leaving Media Molecule and starting my new job. I want to explore a few concepts, some of which I think are worth writing up, if only to work the ideas through my fingers. Lip Syncing in virtual reality is an interesting one that seized my grey gooey bits the other day so let us explore it.
The issues with computers are they like numbers. If we were to take a full-colour high-resolution photo of your lips, it would be somewhat useless as we would need to convert colour pixels into red, green and blue floats—one for every pixel. So the first simplification is to use Luma, a type of greyscale image. Then instead of using a high-resolution image, use a lower resolution image. Working at lower resolutions also allows us to work at higher framerates which you will see come into play later.
Our approach could branch into tracking a volumetric dataset and building a 3d model, a generic and highly potent system that, while more data-intensive, allows this method to work on all face shapes, including those with medical conditions or some future two mouthed alien we encounter. The limitation of this approach is it will only ever show what's real and is an absurdly large volume of data, especially in a large space with many people. We will put this approach in our pocket for later discussions and instead wonder how we can break it down into more abstract data. Think about it as the difference between a picture and a drawing or vector illustration.
Motion Vectors
Feature tracking and filtering allows us to boil the image down to a set of tracked points but doing this all in software could be a pain. It turns out through a beautiful instance; the data needed to improve video encoding can help us. You see, cameras get this raw image data, but instead of saving it to lots of bitmaps, we compress it into JPEGs or similar, and for video, we use interpolation frames, commonly called I-frames. More complex variations exist but aren't helpful to the discussion. This work is computationally complex, and camera manufacturers wanted to reduce cost, complexity and size, so they developed specialised silicon, which is purpose-built to find motion vectors and gradients.
Motion vectors, simply put, are a data store of the pixel colour and the estimated motion that pixel has moved. They are useful because if a car drives across the frame, we can re-use data when encoding to compressed video formats with I-frames. For us, it provides some useful motion data to allow us to pick out features. Hardware in some devices allows fast detection of gradients mostly used for digital focus algorithms but is also extremely useful for detecting features in images.
Building on these fortunate developments allowed computer vision software to get a boost in the last decade. When breaking down a face, we are often looking for motion and gradients. Things like the eyebrows, the shadows they cast on your eyes, the distinct shadow under your nose and the shading of your chin and lips help us anchor our model. Complications like facial hair, long fringes and glasses are just added complexity. Though in the end, we should have a facial feature track with between 8 and 64 points depending.
The final step is don't think of these points as full 3d positions; instead, we can encode this data down further to relative spaces and reduce the inputs we need to feed into our system.
Visemes
The issue now is one of output. We don't want to generate a deep fake or some other image data. We want to drive an animation. Something that algorithms are good at is tacking that set of values and developing a set of confidence values or a conceptual point in space; approaches vary. The easiest way I can explain a common practice is to imagine we map the mouth open to the Y value on a chart, and then we map the wideness value to the X value on a chart. For any combination of mouth open and wideness, there is a valid representation on this chart. So the algorithm just needs to place a point on the chart.
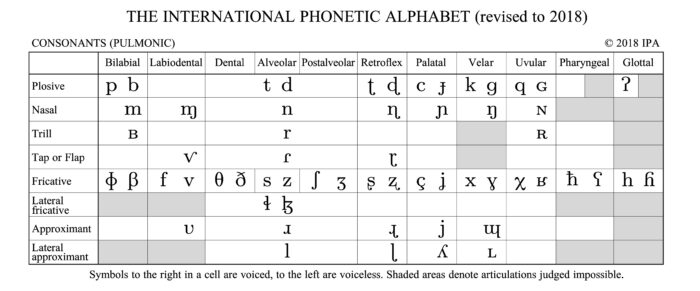
Perhaps the most exciting place to start is giving our current biology and limits of the human range. We know that there are only so many sounds the human mouth can make. The Phonetic Alphabet is based on sounds rather than mouth shapes, but its an excellent place to start. As a result, we also know there are a limited number of forms the mouth can take. Outside of the silly faces and blowing raspberries, the focus can be placed precisely on speaking.
Try opening your mouth as much as possible, making a tall O shape. Now smile, smile more and make your mouth as wide as possible, making a long dash shape. Those are our limits but notice you cannot have a fully open and wide mouth. Instead of an infinite plane, we form instead of a find of oval shape where the point can be on the paper. This geometry is our possibility space. I have say eight expressions that map the possible mouth manipulations. We build this complex 8th-dimensional possibility space which is easy to talk about with maths and computers but very hard to visualise. It will have very likely spots and improbable spots with edges fading to impossibility.
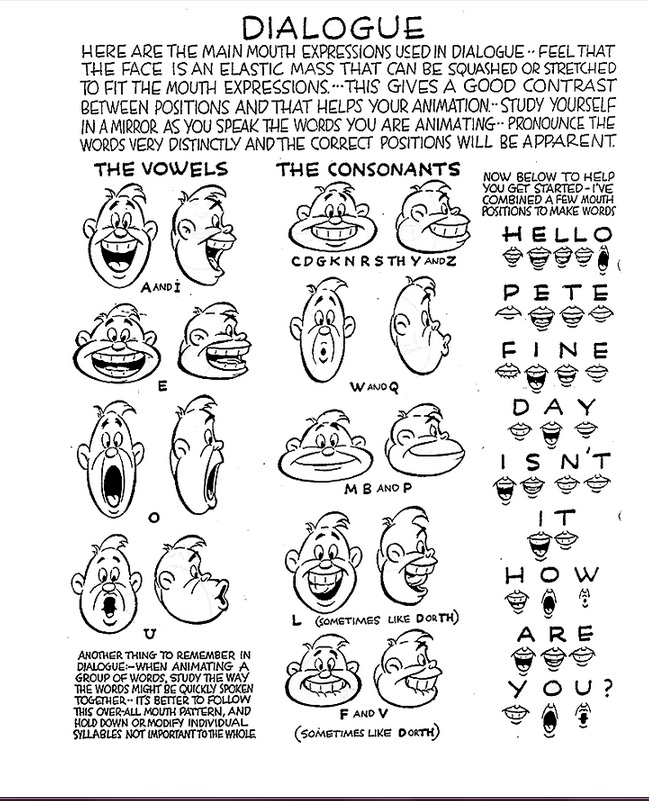
My first exposure to mouth shapes was the classic animator's handbook which so many have poured over for its depth of knowledge. This page should look familiar. This breaking down into shapes rather than sounds allows us to merge into a smaller problem space than the full phonetic alphabet. The most common use case I think most VR denizens and artists will face are the VRChat Visemes.
I have heard Visemes describe as representing an axis in that possibility space. This is an okay approach but leads to smearing and, honestly, a larger dimensional space than is needed. A better system is to take those hot spots of high probability I mentioned before, being sure to have points near the edge represented and build a set of points, like planets floating in this multidimensional space, each with their own gravity. You don't care where you are in space but rather which planet, or maybe two or three planets, are nearest to you—giving you the mouth shape you need to create from 1-3 blend shapes: the fewer shapes, the more distinct and readable but the less smooth the transition.
Japanese vs Western Animators
An important side note in this discussion revolves around Anime and the Japanese language. The IPA chart I put above is representative of all languages, not just English. Some languages use more and others less. English with its habit of beating up other languages and stealing their grammar and vocab, has a pretty broad presentation. Though try to get an Englishman to roll his Rs or a fine Lady to get the plosives of Xhosa, and you will have a fun time laughing. For various reasons, Japanese has very few sounds comparatively but also focuses on the sounds with not much rounding or mouth manipulation.
Studies have shown that native Japanese speakers barely use lip reading to help to understand words. By comparison, English speakers have auditory hallucinations based on what they see, allowing for a wider range than the pure audio. Don't believe me watch this video from BBC Horizon on the McGurk effect. As a result, animators in Disney and the like have whole departments dedicated to lip-syncing as it's critical to sell the character.
By comparison, Japanese animation has mostly made mouth flaps, or envelope tracking, with only the occasional emotional scene getting the full lip treatment. This has a substantial cultural effect but also an impact on technology. It's no secret that Japan & China lead the way in Virtual Reality and a critical but tangential area, Virtual Avatars. VTuber tech of today, and much of the motion capture tech, was developed in Japan. As such, engineering effort has been spent in certain places and not in others. This also bleeds out into content like the dominance of Japanese art in VRChat, leading to less emphasis on distinct Visemes. Some plugins even generating smoothed out estimates of key shapes based on 2-4 example shapes.
Virtual Reality and New Devices
With HTC once again teasing their lip tracker, years after it's debut in the dev space, and other big players entering the space, it's time to talk devices. The HTC device is a dedicated lip tracker camera, purpose-built for this tracking. The Decagear has both an upper and lower face camera for tracking, so they will have a dedicated lip tracker. Additionally, we know Facebook is developing a range of solutions. Many other's have projects not yet in the public space but safe to say the facial tracking cameras will be standard tech in new headsets within five years.
Remember how earlier I talked about luma cameras and high framerates. That matters because the most effective cameras use infrared LEDs and because your skin is more distinct under IR light. Also, facial hair is easier to ignore, and items such as glasses show out more distinctly. Another benefit is most make-up does not affect this. The high framerates give better motion vectors and allow higher confidence by tacking multiple frames of data and smoothing the result. Some models even apply movement constraints to avoid jumping data points.
The camera isn't the only data source the HMD also have microphones that allow us to map mouth shapes and phonetics to improve the models. Additionally, muscular or electrical sensors on the interfacing plate can also drastically improve the tracking. Open your hands into a loose shape like your holding a large ball and place your fingers below your eyes where your VR faceplate rests. Now make all the funny mouth shapes you can think of and talk, notice how distinct your skin and muscles' movement under your fingertips is?
I should point out everything we are talking about here is already technically BCI, Brain-Computer Interface, much like your keyboard is. The really juicy stuff is EEG & fNIRS but let's leave those topics aside for another discussion.
So this all provides a robust lip-sync and viseme based platform, and I think it will be the approach most tech takes—finally, one last side note on facial tracking vs lip sync.
Facial Tracking vs Volumetric Models
Now I've been focused on lip sync, but the conversation extends out into facial tracking easily, and you can look at Hypersense, now owned by Unreal devs Epic Games, or the FaceID work in mobile phones like Apple to see how this scales out. Instead of Visemes, they have a range of channels, some of which interact and others that don't. Your tongue sticking out does not affect your eyebrow position, for example. However, the approach is broadly the same.
Remember our two mouth alien? Well, it turns out some people fall out of the normal dataset, and for these people, this data modelling approach really sucks, and you could see some digital exclusion happening. We already say this with early face tracking on some racial groups or even just people with longer hair. Also, this approach is limited in scope, so when Ace Ventura walks onto the digital stage, we cannot capture that full range of motion. The solution to this many will point to is volumetric capture and playback.
There is no real difference between volumetric playback and capture than video from a webcam with the noted exception of depth. As such, it is creatively limited. Snap filters or their holograph equivalent are possible. Beauty filters that remove double chins and even emotional filters which hide nervous ticks or solve resting bitch face for those us lucky enough to have a face destined for galactic conquest. Ultimately though, you are sending a much larger amount of data. Instead of 16-80 floats compressed in relative space, you send a high resolution 360 video with depth information. Using facial models, you could compress the data, but then you get all the negatives already discussed without the freedom of a full abstraction.
The shift from traditional animation to computer animation saw this pain point with hard rigged models limiting animators' creative freedom. Over time they started building bespoke tools, and modern animation flows quickly flesh out scenes with automatic lip-sync tech or motion capture. Animators later tweak and sculpt with all the freedom of traditional animation, even replacing the face entirely. Tweaks can be done with canned animations, or if the confidence value is low enough in the model, you could switch to a point mapping distortion from the HQ source or a range of other fill-ins. I'm confident though even with these bells and whistles, the double-edged blade of compression and standardisation will push us into standardised data formats for a wide range of applications. Much how phone calls could be significantly higher quality, and once were, but economics and technology ushered us down a compressed VOIP line which brutalises hold music.
Conclusion
All that taken equal the TLDR is
- Facial tracking hardware based on audio, IR camera and skin contacts will be widely available within five years
- Tracking models will settle into a handful of abstract data standards
- Expect Visemes and Blend Shapes to dominate with custom animations sprinkled in
- High-End volumetrics will be used in limited cases but lose out due to bandwidth and creativity